
Resulta que he estado “liadillo” estos días con el TFM, pero al fin parece que estoy libre y listo para retomar este cajón desastre. Hoy, tras leer un artículo publicado recientemente en “Pattern Recognition” [1], tengo la intención de presentar algunos conceptos básicos, problemas y algún que otro ejemplo simple sobre algoritmos de detección de círculos.
El primer nombre que surge al buscar información sobre métodos de detección de círculos es Hough. Más concretamente, un método ampliamente aceptado basado en la “Circle Hough Transform (CHT)” que parece que funciona bastante bien en términos de localización, aunque presenta algunos “problemillas” relativos al tiempo de cómputo. Precisamente son esos problemas los que motivan la existencia de algoritmos alternativos como poner ejemplo el presentado en el artículo referido al comienzo. Ese artículo en concreto usa algo conocido como “circle power theorem” y “power histogram” para conseguir detectar círculos en imágenes ruidosas consiguiendo reducir el tiempo de cómputo necesario. Es bastante interesante pero hoy, la idea es simplemente entender el método CHT.
La idea escondida tras el “Hough Transform method” es identificar todas las líneas/cuadrados/círculos o lo que sea que se está buscando que pasen por los píxeles blancos de una imagen binaria registrando los candidatos en una matriz de acumulación. Posteriormente, los candidatos que más se repiten se consideran detecciones positivas. La dificultad normalmente reside en la forma en la que se describe la geometría que se quiere encontrar.
En el caso particular de un círculo, la ecuación paramétrica a utilizar sería:

Donde 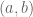

Para explicar esta técnica, normalmente se comienza asumiendo que se buscan círculos de radio conocido, y luego, se generaliza la interpretación.
Considerando que se está buscando un círculo de radio conocido en una imagen ideal (que solo contiene el círculo objetivo), si se acumulan los centros de todos los círculos candidatos en una matriz, resulta lo siguiente.
Como puede verse, mientras que el proceso de búsqueda progresa, le matriz de acumulación presenta un pico justo en la posición que corresponde al centro a detectar. Sin embargo, cuando el radio es desconocido, la representación no es tan sencilla puesto que se ha de considerar una nueva dimensión.
Una posible forma de ilustrar esta idea, es construir conos en cada pixel-blanco, correspondiendo cada nivel en z con un radio distinto. La siguiente figura pretende representar este proceso de búsqueda. En ella puede verse como, para el valor de radio correcto, se detecta un pixel “brillante” en el centro de la representación de la matriz de acumulación.

Ahora, pasamos a aplicar el método (código disponible AQUÍ) primero sobre una imagen sintética, y luego sobre una real. La siguiente figura muestra una representación dinámica del subespacio resultante donde puedes ver que, cuando se alcanzan los niveles de los radios de los círculos presentes en la imagen, aparecen de nuevo puntos brillantes.

Si se representan los máximos valores registrados en cada uno de los niveles del subespacio, podemos observar tres picos, que probablemente correspondan con los tres círculos presentes.
 Si se define un umbral para discernir entre detecciones positivas y negativas, e iluminamos los círculos detectados, se obtiene la siguiente imagen.
Si se define un umbral para discernir entre detecciones positivas y negativas, e iluminamos los círculos detectados, se obtiene la siguiente imagen.
 Parece que funciona bien … pero claro.. es cierto que es una imagen sintética y por lo tanto, la detección es más sencilla. Entonces veamos qué ocurre al aplicar la técnica a una imagen real. En este caso, al representar el subespacio, no se observan picos tan “diferenciables” como en el caso anterior.
Parece que funciona bien … pero claro.. es cierto que es una imagen sintética y por lo tanto, la detección es más sencilla. Entonces veamos qué ocurre al aplicar la técnica a una imagen real. En este caso, al representar el subespacio, no se observan picos tan “diferenciables” como en el caso anterior.

Sin embargo, cuando se representan de nuevo los valores máximos en cada nivel del subespacio, sí que se diferencian algunos candidatos potenciales.
Si aplicamos de nuevo un umbral, y se iluminan las detecciones positicas, resulta que sí que hemos detectado los círculos principales de la foto. Aunque aparecen por ahí algunos círculos que uno no esperaría (falsos positivos?).

Las conclusiones que extraigo de este breve trabajo son las siguientes:
- Resulta que la “transformada de Hough” que conocía para la detección de líneas, puede generalizarse para la búsqueda de cualquier otra geometría.
- El tiempo de cálculo de este método es una de las grandes desventajas.
- Una vez obtenida el subespacio de acumulación, la tarea de decidir qué se considera una detección positiva-negativa no es para nada trivial.
Algún día sería interesante explorar el método presentado al principio de este post, pero ese día no será hoy.
Para cualquier inquietud, abajo tenéis el cajón de comentarios!
Nos vemos pronto.
Referencias.
[1] B. Yuan and M. Liu. Power histogram for circle detection on images. Pattern Recognition, 2015.

 Parece ser que hay varias maneras de medir dicha propiedad. Entre todas ellas, destacan dos métodos: basados en kernels Vs métodos frecuenciales. Los métodos basados en Kernels consisten básicamente en registrar la diferencia entre cada pixel y el valor medio de su vecindad. Mientras mayor sea esa diferencia, mayor es la probabilidad de tratarse de una región enfocada. Asumiendo que la imagen a procesar contiene alguna zona enfocada, los valores más altos se registrarán en dichas regiones.
Parece ser que hay varias maneras de medir dicha propiedad. Entre todas ellas, destacan dos métodos: basados en kernels Vs métodos frecuenciales. Los métodos basados en Kernels consisten básicamente en registrar la diferencia entre cada pixel y el valor medio de su vecindad. Mientras mayor sea esa diferencia, mayor es la probabilidad de tratarse de una región enfocada. Asumiendo que la imagen a procesar contiene alguna zona enfocada, los valores más altos se registrarán en dichas regiones.![Kernel = \left[\begin{array}{ccc} 0 & -1& 0 \\-1 & 4 & -1 \\ 0 & -1 & 0 \end{array}\right]](https://s0.wp.com/latex.php?latex=Kernel+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccc%7D++0+%26+-1%26+0+%5C%5C-1+%26+4+%26+-1+%5C%5C+0+%26+-1+%26+0++%5Cend%7Barray%7D%5Cright%5D+&bg=ffffff&fg=555555&s=0&c=20201002)

 En la última imagen en blanco y negro, las zonas más oscuras corresponderían a las zonas seleccionadas. Si aplicamos una umbralización a esa imagen, tendremos una imagen binaria (sólo “unos” y “ceros”) con las zonas bien señaladas.
En la última imagen en blanco y negro, las zonas más oscuras corresponderían a las zonas seleccionadas. Si aplicamos una umbralización a esa imagen, tendremos una imagen binaria (sólo “unos” y “ceros”) con las zonas bien señaladas. Este último resultado lo usamos para iluminar píxeles en la imagen original y tenemos lo siguiente.
Este último resultado lo usamos para iluminar píxeles en la imagen original y tenemos lo siguiente.

 —————————-Cómo implementar esto?—————————-
—————————-Cómo implementar esto?—————————-

 y de tamaño
y de tamaño  para no tener que buscar el objeto en toda la imagen. En otras palabras: el objeto se busca en torno al punto en el que suponemos que va a estar el objeto atendiendo a los datos pasados, y el tamaño de esa región de búsqueda dependerá de alguna forma de la incertidumbre de esa estimación. La siguiente imagen intenta mostrar por qué el tamaño de la ventana es una función de la velocidad.
para no tener que buscar el objeto en toda la imagen. En otras palabras: el objeto se busca en torno al punto en el que suponemos que va a estar el objeto atendiendo a los datos pasados, y el tamaño de esa región de búsqueda dependerá de alguna forma de la incertidumbre de esa estimación. La siguiente imagen intenta mostrar por qué el tamaño de la ventana es una función de la velocidad.



 . Dados dos instantes consecutivos
. Dados dos instantes consecutivos  y
y  , queremos calcular el flujo óptico, más concretamente un campo de velocidades que representa la diferencia entre el frame en
, queremos calcular el flujo óptico, más concretamente un campo de velocidades que representa la diferencia entre el frame en  .
.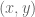 , buscamos la velocidad
, buscamos la velocidad  que describe el cambio de posición de dicho pixel de un frame a otro.
que describe el cambio de posición de dicho pixel de un frame a otro.




 del pixel evaluado tiene la misma velocidad que el de interés, por lo que se podría escribir:
del pixel evaluado tiene la misma velocidad que el de interés, por lo que se podría escribir:



 donde
donde


 debe tener rango completo.
debe tener rango completo.